Cookiebot-Driven Solutions: Enhance Your Site's Personalization
Cookiebot-Driven Solutions: Enhance Your Site’s Personalization
Back to The Intelligent Enterprise
Experimenting with Different AI Techniques to Accurately Crop Identity Documents
by Boris Zimka, Principal Software Engineer
Photographs of identification documents such as passports and ID cards are highly subject to geometrical distortion. We must remove the distortion by identifying the polygonal contours of the ID card/passport. To do this, we wanted to discover the most effective methods for cropping these documents. We tested several different techniques.
The content of this article is based on a presentation that the author delivered at DSC Europe.
The core idea of Occam’s Razor is parsimony or simplicity. In various forms, it states that among competing hypotheses that predict equally well, the one with the fewest assumptions should be selected. In other words, the simplest explanation is usually preferred because unnecessary complexities and “entities” should not be assumed without necessity. This principle is a staple in scientific methodology, often guiding researchers to opt for theories with the simplest, most straightforward explanations.
This way of thinking also comes handy in different areas of engineering, specifically in AI engineering. In most cases, there can be many solutions for the same problem—and choosing the right one is not an easy task. We learned this deeply while experimenting to find the best possible solution to detect and crop identity documents in any shape or form, in every scenario imaginable…whether that’s a scan or a photo of a cat holding a passport.

Image generated using DALL-E.
Photographs of identification documents such as passports and ID cards are highly subject to geometrical distortion. We must remove the distortion by identifying the polygonal contours of the ID card/passport. To do this, we wanted to discover the most effective methods for cropping these documents. We tested several different techniques for identifying the polygonal contours of the documents to identify the most accurate and effective approach.
Approach #1: Projective transformation estimation
The first method we used to do this was based on projective transformation estimation. Since a rigid ID document is a rectangular segment of a 3D plane in 3D space, we must be able to map the document when the plane is skewed. For this, we need to train the neural network to predict projective transformation parameters. In this process, the network estimates the transformation parameters in such a way that the image corners are mapped into ground truth corners.
In most experiments, we used the Lite-HRNet architecture, a network that was used in research papers (see references below) to estimate the pose that a human being has in an image, and it delivers a good balance of quality and speed for this similar task. To make it work, we replaced the usual MSE loss with its circular version. Instead of minimizing one specific matching of key points, we minimize the best possible matching, which is defined by circular rotation.

As there are no common metrics for quality in this process, we defined our own, choosing them according to their importance to our downstream model. The most straightforward way to estimate if two polygons are similar is to calculate intersection-over-union. It was crucial to minimize the number of critical errors, i.e., cases when the prediction is so bad that it later actually harms document recognition. Meanwhile, we found that minor errors, where intersection-over-union was close to 90 percent, were not important for document recognition quality.
Unfortunately, we determined that projection estimation is not very effective in terms of critical errors. In the presence of critical errors, such as shown below, it becomes impossible for other models in our document processing pipeline to do their job well.

Blog
ABBYY Spotlight: Mihajlo Mulic, Senior Software Developer, Serbia
Approach #2: Heatmap estimation
Next , we tried another popular technique that is based on heatmap estimation. The idea behind this approach is that we can estimate the probability of a key point to be found at some location as a heatmap. To train the network, we need a target. One option here is to use a so-called soft-argmax operation. This operation normalizes the predicted heatmap with softmax activation and then calculates its center of mass. Soft-argmax is differentiable, and does not require additional hyperparameters, so we used it in our pipeline.
The heatmap-based approach with soft-argmax has shown two times fewer errors than the projection-based approach. One problem that still annoyed us were so-called “out-of-image” key points. The heatmap-based approach only allows for finding a key point inside the image. However, when a document photo is taken by a smartphone, in 10 percent of cases, one or several corners happen to be outside of the actual visible parts of the image. Choosing the closest point on the image border leads to geometric distortion, and it often cuts out a meaningful part of the image, which is detrimental to our entire pipeline quality.

Many key point estimation networks use so-called “offsets” to make their predictions more precise. Similar to object detection, the network is trained to predict not only probabilities of objects but also some kind of vector toward the object’s position. We tried this approach, but for our case with out-of-image key points, it did not make any significant improvements. Instead, we solved this problem with one simple trick: we added some padding around the processed images, so the network can find corners slightly beyond the actual image frame. This trick reduced the number of critical errors by 15 percent.
Approach #3: Differentiable rasterization
One feature that we did find useful in the above approach was to predict masks for a document body and document border. In vector form, corners and masks are directly related: corners define the polygon; the polygon defines the corners. This led us to explore the idea of using this vector form for training. It turns out that this is possible using a trick called differentiable rasterization.
Rasterization is a process of calculating a polygon mask when we know its corners. There are multiple algorithms to rasterize, one of the most popular being “point-in-polygon.” For every pixel, this algorithm checks whether the point is inside the polygon or not.
The problem with this method is that rasterization is not a differentiable process. Every point is either inside or outside; the rasterized values are 0 or 1, so the derivative is 0 everywhere. We wanted to rasterize the mask from the corners and use it in training, so we needed rasterization to be differentiable.
Luckily, a differentiable version of this process exists, and it even has a PyTorch code. The idea is that, instead of checking if a point is inside or outside of a given polygon, we can imagine a circle area around the point and measure what fraction of the circle is inside of the polygon. This leads to similar outcomes for locations that are far from the border; but near the border, we have an area of gradient.
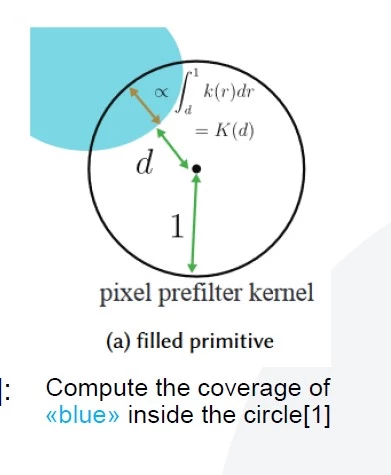
So now, the network head predicts some key points, and the polygon composed from these points is differentiable rasterized, and compared with the ground-truth mask. This approach allows us to optimize intersection-over-union and metrics directly. Usually, direct optimization of metrics leads to better results.
Applying this approach mainly to passports, we experienced some pitfalls:
- Key points can be disordered.
- Polygons can contain self-intersection.
- Key points can collapse close to each other.
- Polygons can turn inside out.
In the end, we decided to abandon this approach, because it failed to achieve high enough results.
Approach #4: Sampling argmax
Finally, we went back to a heatmap-based pipeline and started looking for a way to improve it. One problem that kept occurring was multi-peak heatmap distributions, for example, where both corners get into the same channel. This leads to significant errors. To improve this, we experimented with one more technique called sampling argmax, designed specifically to address this problem.
This approach is adapted from soft-argmax. It samples several points from the heatmap distribution and then applies loss to these samples. For example, assume that the network has predicted a multi-peak heatmap. When we try to get a sample from this distribution, the most likely outcome is that we will get a sample close to the biggest heatmap peak. But if we keep sampling, at some point we will get a sample from the other peak, too. Since there can only be one correct match, one of these two variants will get a high loss. In the end, it teaches the network that it is not only important to place the mean of the heatmap near the ground truth but to concentrate the probability mass distribution as much as possible.


Sampling differentiably from categorical distribution can be done with a method called the Gumbel-Softmax trick. This trick is not so simple—see the paper references section at the bottom of the article!
With sampling argmax, we got much more precise heatmaps and consistent masks. The network learned to stick to a single variant instead of combining multiple into one. It also reduced the amount of critical errors by 10 percent.
Conclusion
Our goal is always to provide the most accurateintelligent document processing technology for our customers. After experimenting with the various techniques, the wisdom behind Occam’s Razor rings true. To achieve high-quality results, one needs to try multiple possible solutions. And when in doubt about which to choose…stick to the simplest one.
*All ID documents shown in this article are not real and are intended only for demonstration purposes.
Supporting research:
- Arlazarov, Vladimir Viktorovich, et al. “MIDV-500: a dataset for identity document analysis and recognition on mobile devices in video stream.” Компьютерная оптика43.5 (2019): 818-824.
- Yu, Changqian, et al. “Lite-hrnet: A lightweight high-resolution network.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
- Wang, Xinyao, Liefeng Bo, and Li Fuxin. “Adaptive wing loss for robust face alignment via heatmap regression.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
- Sun, Xiao, et al. “Integral human pose regression.” Proceedings of the European conference on computer vision (ECCV). 2018.
- Li, Tzu-Mao, et al. “Differentiable vector graphics rasterization for editing and learning.” ACM Transactions on Graphics (TOG) 39.6 (2020): 1-15.
- Zorzi, Stefano, et al. “Polyworld: Polygonal building extraction with graph neural networks in satellite images.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
- Li, Jiefeng, et al. “Localization with sampling-argmax.” Advances in Neural Information Processing Systems 34 (2021): 27236-27248.
Subscribe for updates
Get updated on the latest insights and perspectives for business & technology leaders
First name*
Last name
E-mail*
Сountry*
СountryAfghanistanAland IslandsAlbaniaAlgeriaAmerican SamoaAndorraAngolaAnguillaAntarcticaAntigua and BarbudaArgentinaArmeniaArubaAustraliaAustriaAzerbaijanBahamasBahrainBangladeshBarbadosBelgiumBelizeBeninBermudaBhutanBoliviaBonaire, Sint Eustatius and SabaBosnia and HerzegovinaBotswanaBouvet IslandBrazilBritish Indian Ocean TerritoryBritish Virgin IslandsBrunei DarussalamBulgariaBurkina FasoBurundiCambodiaCameroonCanadaCape VerdeCayman IslandsCentral African RepublicChadChileChinaChristmas IslandCocos (Keeling) IslandsColombiaComorosCongo (Brazzaville)Congo, (Kinshasa)Cook IslandsCosta RicaCroatiaCuraçaoCyprusCzech RepublicCôte d’IvoireDenmarkDjiboutiDominicaDominican RepublicEcuadorEgyptEl SalvadorEquatorial GuineaEritreaEstoniaEthiopiaFalkland Islands (Malvinas)Faroe IslandsFijiFinlandFranceFrench GuianaFrench PolynesiaFrench Southern TerritoriesGabonGambiaGeorgiaGermanyGhanaGibraltarGreeceGreenlandGrenadaGuadeloupeGuamGuatemalaGuernseyGuineaGuinea-BissauGuyanaHaitiHeard and Mcdonald IslandsHoly See (Vatican City State)HondurasHong Kong, SAR ChinaHungaryIcelandIndiaIndonesiaIraqIrelandIsle of ManIsraelITJamaicaJapanJerseyJordanKazakhstanKenyaKiribatiKorea (South)KuwaitKyrgyzstanLao PDRLatviaLebanonLesothoLiberiaLibyaLiechtensteinLithuaniaLuxembourgMacao, SAR ChinaMacedonia, Republic ofMadagascarMalawiMalaysiaMaldivesMaliMaltaMarshall IslandsMartiniqueMauritaniaMauritiusMayotteMexicoMicronesia, Federated States ofMoldovaMonacoMongoliaMontenegroMontserratMoroccoMozambiqueMyanmarNamibiaNauruNepalNetherlandsNetherlands AntillesNew CaledoniaNew ZealandNicaraguaNigerNigeriaNiueNorfolk IslandNorthern Mariana IslandsNorwayOmanPakistanPalauPalestinian TerritoryPanamaPapua New GuineaParaguayPeruPhilippinesPitcairnPolandPortugalPuerto RicoQatarRomaniaRwandaRéunionSaint HelenaSaint Kitts and NevisSaint LuciaSaint Pierre and MiquelonSaint Vincent and GrenadinesSaint-BarthélemySaint-Martin (French part)SamoaSan MarinoSao Tome and PrincipeSaudi ArabiaSenegalSerbiaSeychellesSierra LeoneSingaporeSint Maarten (Dutch part)SlovakiaSloveniaSolomon IslandsSouth AfricaSouth Georgia and the South Sandwich IslandsSouth SudanSpainSri LankaSurinameSvalbard and Jan Mayen IslandsSwazilandSwedenSwitzerlandTaiwan, Republic of ChinaTajikistanTanzania, United Republic ofThailandTimor-LesteTogoTokelauTongaTrinidad and TobagoTunisiaTurkeyTurks and Caicos IslandsTuvaluUgandaUkraineUnited Arab EmiratesUnited KingdomUnited States of AmericaUruguayUS Minor Outlying IslandsUzbekistanVanuatuVenezuela (Bolivarian Republic)Viet NamVirgin Islands, USWallis and Futuna IslandsWestern SaharaZambiaZimbabwe
I have read and agree with the Privacy policy and the Cookie policy .*
I agree to receive email updates from ABBYY Solutions Ltd. such as news related to ABBYY Solutions Ltd. products and technologies, invitations to events and webinars, and information about whitepapers and content related to ABBYY Solutions Ltd. products and services.
I am aware that my consent could be revoked at any time by clicking the unsubscribe link inside any email received from ABBYY Solutions Ltd. or via ABBYY Data Subject Access Rights Form .
Referrer
Query string
GA Client ID
UTM Campaign Name
UTM Source
UTM Medium
UTM Content
ITM Source
Page URL
Captcha Score
Connect with us
Also read:
- [Updated] Advanced Array Manipulations and Sorting Algorithms
- Apple's Future Vision: Introducing Camera-Equipped AirPods Set to Release in 2026, According to Insider Sources
- Audio Mastery in Visual Storytelling Vimeo Edition
- End the Frustration: Proven Strategies for Fixing Crashes in Oxygen Not Included
- Fix Your Steam Crashes Instantly - Simple Solutions!
- Hervé Laurandin as Nouveau Directeur De ABBYY en France: Une Évolution Stratégique
- IPhone Document Scanning & Conversion with OCR: Mastering Text Recognition Using FINEREADER
- Master the Art of AI Prompts with These 5 Exceptional Online Classes
- Mastering Hackathon Excellence: Strategies for Promoting Innovative Thinking & Achieving Successful Results
- Mastering the Art of Page Optimization for Search Engine Success
- Outsourcing and Shared Service Week: ABBYY's Role in Industry Discussions
- Ultimate Solution for Cyberpunk 2077 Computer Freezing Issues
- Understanding Facebook's Video Privacy Settings

- Title: Cookiebot-Driven Solutions: Enhance Your Site's Personalization
- Author: Larry
- Created at : 2024-10-01 01:44:38
- Updated at : 2024-10-06 00:38:49
- Link: https://discover-brilliant.techidaily.com/cookiebot-driven-solutions-enhance-your-sites-personalization/
- License: This work is licensed under CC BY-NC-SA 4.0.